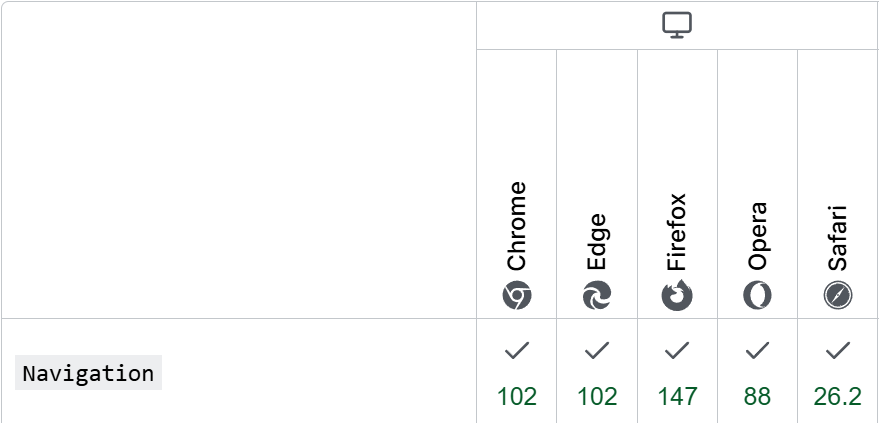
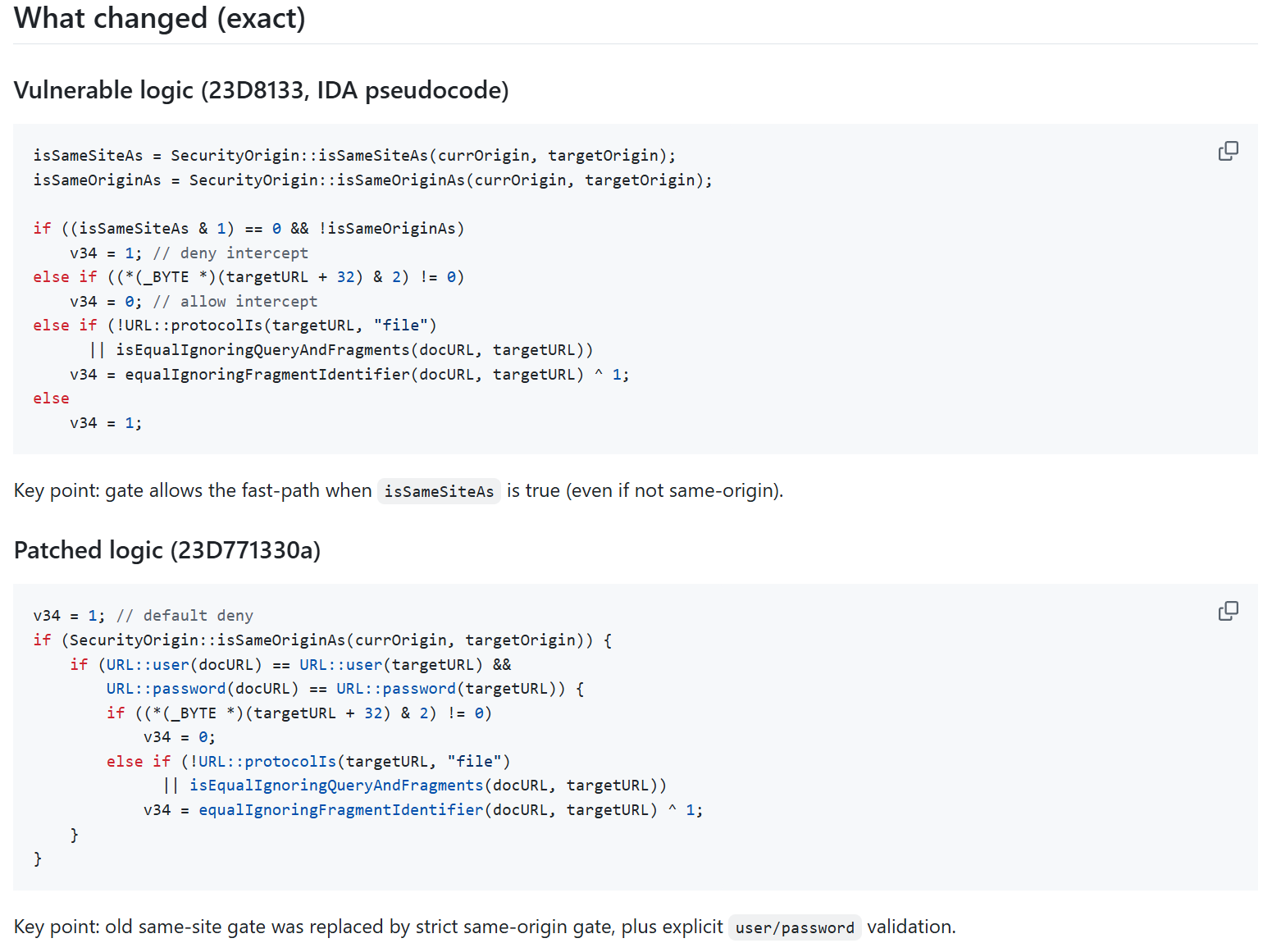
在现代 web 开发中,Blob(Binary Large Object) 是一个重要的概念,广泛应用于处理二进制数据,如图像、视频等。本文将分享我如何利用 ChatGPT,从初步了解 Blob 的原理,到最终生成一个用于下载视频的 Chrome 插件的完整过程。希望能为正在进行类似项目的开发者提供一些参考和启发。
目录
- 引言
- 初探 Blob API
- 利用 ChatGPT 深入理解 Blob
- 从 Blob 到 Chrome 插件开发
- 实现 Chrome 插件
- 总结
- 参考资料
- License
引言
故事要从一个朋友问我的问题说起,买的网课要到期了来不及看完,手机录屏录不了有没有什么办法可以把视频都录下来。我说,有网页版吗,打开QQ录屏就行了,试了一下确实可以,It works! 不过,对于专业人士来说,不够优雅,于是我打算让ChatGPT老师帮我解决这个问题,从询问原理开始,最终达成了用ChatGPT写出了一个自动下载视频的Chrome插件。
初探 Blob API
Blob(Binary Large Object)是用于存储二进制数据的对象,常用于处理文件数据、图像、视频等。在浏览器中,Blob 常与 URL.createObjectURL 方法配合使用,将二进制数据转换为 URL,从而在页面上展示或下载。
基本使用示例:
1
2
3
4
5
6
7
8
9
10
11
12
|
const blob = new Blob(["Hello, world!"], { type: "text/plain" });
const url = URL.createObjectURL(blob);
const link = document.createElement('a');
link.href = url;
link.download = 'hello.txt';
link.textContent = 'Download Hello.txt';
document.body.appendChild(link);
|
通过上述方法,可以在不上传服务器的情况下,生成可供下载的文件链接。
利用 ChatGPT 深入理解 Blob
在决定开发 Chrome 插件之前,我需要深入理解 Blob 的工作原理以及如何在网页中拦截和操作 Blob URL。这时,我利用了 ChatGPT 的强大语言理解和代码生成能力。
询问 Blob 原理
首先,我向 ChatGPT 提出了关于 Blob 原理的问题:
问题:什么是 Blob?它在浏览器中的作用是什么?
ChatGPT 的回答:Blob(Binary Large Object)是一种用于存储二进制数据的对象,常用于处理文件、图像、视频等。在浏览器中,Blob 主要用于以下几个方面:
- 文件上传和下载:通过 Blob 可以生成可供下载的文件链接。
- 图像和视频处理:使用 Blob 存储和操作媒体数据。
- 数据传输:在客户端和服务器之间传输二进制数据时,Blob 起到中间媒介的作用。
ChatGPT 的详细解释帮助我全面掌握了 Blob 的基本概念和应用场景,为后续的插件开发奠定了坚实的理论基础。
生成代码示例
接下来,我需要在实际项目中操作 Blob。因此,我向 ChatGPT 请求生成相关的代码示例:
问题:如何在网页中拦截 Blob URL 并下载对应的视频文件?
ChatGPT 的回答:
要拦截 Blob URL 并下载对应的视频文件,可以通过重写 URL.createObjectURL 方法,并监听视频元素的相关事件。以下是一个基本的实现示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| (function() {
const originalCreateObjectURL = URL.createObjectURL;
URL.createObjectURL = function(blob) {
const blobUrl = originalCreateObjectURL.call(this, blob);
console.log('Blob URL created:', blobUrl);
if (blob.type.startsWith('video/')) {
const link = document.createElement('a');
link.href = blobUrl;
link.download = `video_${Date.now()}.mp4`;
link.click();
console.log('Video downloaded:', link.download);
}
return blobUrl;
};
})();
|
这个代码片段通过重写 URL.createObjectURL 方法,拦截生成的 Blob URL,并在识别到视频类型的 Blob 时,自动创建并点击下载链接,将视频文件保存到本地。
通过 ChatGPT 生成的代码示例,我对如何操作和拦截 Blob URL 有了更直观的理解,也为后续的插件开发提供了实用的参考。
从 Blob 到 Chrome 插件开发
了解了 Blob 的原理和操作方法后,我决定将其应用到 Chrome 插件的开发中。目标是创建一个插件,能够在用户访问包含视频的网页时,自动拦截并下载正在播放的视频。
具体步骤包括:
- 需求分析:明确插件的功能和工作流程。
- 编写内容脚本:负责在加载网页时注入拦截逻辑。
- 修改 Blob 相关方法:实现拦截和下载功能。
- 管理视频数据:处理被拦截的视频数据并保存。
- 配置manifest.json:定义插件的基本信息和权限。
- 测试插件:确保插件在不同网页和视频环境中正常工作。
实现 Chrome 插件
需求分析
插件的主要功能是:
- 拦截视频加载:识别并拦截通过 Blob URL 加载的视频资源。
- 自动下载视频:将拦截到的视频数据保存到用户的本地设备。
- 用户友好:提供友好的提示和下载管理功能。
编写内容脚本
内容脚本是插件的核心部分,负责在网页加载时注入拦截逻辑。以下是我的 content.js 实现:
1
2
3
4
5
6
7
|
var script = document.createElement('script');
script.src = chrome.runtime.getURL('script.js');
console.log(script.src);
(document.head || document.documentElement).appendChild(script);
|
这个脚本的作用是动态加载 script.js,将拦截逻辑注入到网页的上下文中。(这里需要解释一下,为什么需要注入脚本,而不是直接在网页中执行,因为chrome插件的执行环境是独立的,直接执行可以操作DOM,但hook JavaScript方法并不会影响网页中的JavaScript执行环境)
修改 Blob 相关方法
在 script.js 中,我重写了 URL.createObjectURL 和 URL.revokeObjectURL 方法,以实现对 Blob URL 的拦截和管理。在执行URL.createObjectURL的时候自动创建下载链接,并触发下载。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| (function hookCreateObjectURL() {
const originalCreateObjectURL = URL.createObjectURL;
URL.createObjectURL = function (blob) {
console.log(`[Extension Hooked] URL.createObjectURL called with: ${blob}, type: ${blob.type}`);
console.log(`[Extension Hooked] blob size: ${blob.size}`);
const blobUrl = originalCreateObjectURL.call(URL, blob);
console.log(`[Extension Hooked] Blob ${blobUrl} has been created.`);
if(blob.type === 'video/mp4'){
const link = document.createElement('a');
link.href = blobUrl;
link.download = Date.now() + blobUrl + 'saved.mp4';
link.click();
console.log(`[Extension Hooked] Blob ${blobUrl} has been saved.`);
}
return blobUrl;
};
console.log('createObjectURL hooked');
})();
|
获取视频缓存数据
为了更好地管理视频数据,我在 script.js 中添加了对 SourceBuffer 方法的重写,以便捕获视频分段数据,并在视频加载完成后,合并并下载完整的视频文件。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| const sourceBufferMap = new Map();
(function hookAppendBuffer() {
const originalAppendBuffer = SourceBuffer.prototype.appendBuffer;
SourceBuffer.prototype.appendBuffer = function (data) {
console.log(`[Extension Hooked] SourceBuffer.appendBuffer called with: ${data}`);
if(sourceBufferMap.has(this)){
var mediaSegment = sourceBufferMap.get(this);
mediaSegment.push(data);
}else{
sourceBufferMap.set(this, []);
var mediaSegment = sourceBufferMap.get(this);
mediaSegment.push(data);
}
originalAppendBuffer.apply(this, [data]);
console.log(`[Extension Hooked] source ${data} has been appended.`);
};
console.log('SourceBuffer.appendBuffer hooked');
})();
|
在视频缓存结束时,我们需要将收集到的视频片段合并并下载。以下是对 endOfStream 方法的 hook 实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| (function hookEndOfStream() {
const originalEndOfStream = MediaSource.prototype.endOfStream;
MediaSource.prototype.endOfStream = function () {
console.log(`[Extension Hooked] MediaSource.endOfStream called`);
for (const sourceBuffer of this.sourceBuffers) {
console.log('SourceBuffer found:', sourceBuffer);
console.log('Buffered ranges:', sourceBuffer.buffered);
const completeVideo = new Blob(sourceBufferMap.get(sourceBuffer), { type: 'video/mp4' });
const url = URL.createObjectURL(completeVideo);
URL.revokeObjectURL(url);
}
originalEndOfStream.apply(this);
};
console.log('MediaSource.endOfStream hooked');
})();
|
通过这种方式,我们能够捕获视频的每个数据分段,最终合并成完整的视频文件进行下载。
配置 manifest.json
manifest.json 是 Chrome 插件的配置文件,定义了插件的基本信息、权限和脚本等。以下是我的 manifest.json 配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| {
"manifest_version": 3,
"name": "Preload Hook Example",
"version": "1.0",
"description": "Hook fetch before page load",
"permissions": ["tabs", "storage", "activeTab", "scripting"],
"content_scripts": [
{
"matches": ["http://*/*", "https://*/*"],
"js": ["content.js"],
"run_at": "document_start"
}
],
"web_accessible_resources" : [{
"resources": [ "script.js" ],
"matches": [ "http://*/*", "https://*/*" ]
}]
}
|
在这个配置中:
- permissions:声明了插件所需的权限,如访问标签页(
tabs)、存储(storage)、活动标签页(activeTab)和脚本注入(scripting)。
- content_scripts:定义了在哪些网页上注入哪些脚本,以及脚本的执行时机(
document_start 表示在文档开始加载时执行)。
- web_accessible_resources:指定了插件可以在网页上下文中访问的资源,这里是
script.js。
测试插件
完成上述步骤后,我开始在本地环境中测试插件的功能。具体步骤如下:
加载未打包的插件:
- 打开 Chrome 浏览器,进入
chrome://extensions/ 页面。
- 打开右上角的“开发者模式”。
- 点击“加载已解压的扩展程序”,选择包含
manifest.json 的插件目录。
访问包含视频的网页:
- 测试了小红书、B站、YouTube并成功下载视频,其中小红书视频是一整个mp4文件(包含视频流和音频流),B站和YouTube都是一段视频流+一段音频流,需要合并后才能播放。
调试和优化:
- 根据测试结果,调整拦截逻辑和下载机制,确保插件在不同网页和视频类型下都能正常工作。
总结
通过本文的分享,从初步了解 Blob 原理,到借助 ChatGPT 实现 Chrome 插件的开发,整个过程展示了 AI 工具在开发中的巨大潜力。ChatGPT 不仅帮助我快速掌握了相关技术,还提供了实用的代码示例,加速了项目进展。
最后,为什么不是用获取视频流地址的方式下载,而是提取Blob里的缓存呢,存在几个原因:
- 获取视频流地址需要对每个不同的网站进行分析,而提取Blob里的缓存则可以统一处理。
- 有些网站可能会对视频流中的二进制流进行加密,导致直接下载到的视频无法播放,而提取缓存则是解密后的视频。
- 访问视频流地址下载会产生额外的http请求,而提取缓存则是在本地进行操作,对于服务端而言没有任何感知,减少因为下载视频被block的风险。
当然,提取缓存的方式也有缺点,就是只能等待浏览器缓存完成,缓存了多少,下载就有多少,无法做到按需下载。
未来,随着 AI 技术的不断进步,相信开发者们将在更多领域中受益。希望本文能为大家提供一些有价值的参考,激发更多创新的灵感。
参考资料
License
本文遵循 CC BY-SA 4.0。转载请注明出处。
以上就是使用 ChatGPT 从初步了解 Blob 原理到最终开发出一个功能完整的 Chrome 插件的全过程。希望本文能够帮助到正在进行类似项目的开发者,共同推动 Web 技术的发展!
最后,本文也是使用cursor中的ChatGPT自动生成。